







Język
Czy to prawda, że komputer wkrótce zastąpi tłumacza?
Trudno zaprzeczyć, że zainteresowanie ideą tłumaczenia maszynowego od jakiegoś czasu wyraźnie wzrasta. Większość serwisów społecznościowych oferuje już możliwość automatycznego tłumaczenia wpisów. Strony internetowe coraz częściej korzystają z silników tłumaczenia maszynowego do udostępniania treści w różnych językach. Popularny google translate nie jest już tylko interesującym eksperymentem, na który spoglądamy z przymrużeniem oka. Teraz budzi grozę. Dla wielu jest zapowiedzią rychłego końca zawodu tłumacza. Jednak w rzeczywistości oba poglądy biorą się tylko i wyłącznie z niedostatecznej wiedzy, a jeśli rozwój tej technologii nie zostanie zahamowany, przyniesie znacznie więcej korzyści, niż strat. O technologiach w kontekście pracy tłumacza opowiada filolog anglista Marcin Szwed z Uniwersytetu SWPS.
Tłumaczenie automatyczne – eksperymentalne początki
Zacznijmy od tego, z czym w ogóle mamy do czynienia. Tzw. tłumaczenie maszynowe (ang. machine translation, MT) lub „tłumaczenie automatyczne”, jest dziedziną językoznawstwa komputerowego, czyli nauki zajmującej się takimi zagadnieniami, jak sztuczna inteligencja czy wykorzystanie korpusów językowych. Jest to więc nauka i jako taka opiera się na doświadczeniu i eksperymencie.
Pierwszym doświadczeniem, które – jak twierdzi wielu znawców tematu – zapoczątkowało obserwowany dziś gwałtowny rozwój technologii MT, był eksperyment przeprowadzony w Georgetown 7 stycznia 1954 roku, kiedy to eksperci z firmy IBM, wraz z naukowcami z Georgetown University, z powodzeniem uzyskali przekład ok. 60 zdań z języka rosyjskiego na język angielski za pomocą komputera. Maszyna, która została zaprzęgnięta do tego zadania, posiadała w swojej pamięci tylko 250 słów, a jej składnia robocza obejmowała zaledwie sześć reguł, według których ten skromny zasób słów był wykorzystywany do budowania zdań.
Reguły składni komputera z Georgetown także nie były przesadnie skomplikowane – oto ich pełny zestaw:
 Źródło: W. Hutchins, The Georgetown-IBM experiment demonstrated in January 1954 (www.hutchinsweb.me.uk/AMTA-2004.pdf).
Źródło: W. Hutchins, The Georgetown-IBM experiment demonstrated in January 1954 (www.hutchinsweb.me.uk/AMTA-2004.pdf).
Pomimo tego, że zdania przeznaczone do tłumaczenia w ramach eksperymentu były starannie wyselekcjonowane, a samo tłumaczenie było oparte zasadniczo na podstawianiu jednostek leksykalnych, to eksperyment, o którym „The New York Times” napisał dzień później pod nagłówkiem „Szybki, elektroniczny tłumacz bez trudu przekłada rosyjski na angielski”, spowodował falę zainteresowania tłumaczeniem maszynowym, za którą poszły miliony dolarów na dalsze badania.
Rozwój metod tłumaczenia automatycznego
Nic zatem dziwnego, że od tamtego czasu technologia stojąca za tłumaczeniem automatycznym rozwinęła się w znacznym stopniu. W toku intensywnych badań wypracowano wiele różnych metod tłumaczenia maszynowego, jedną z których jest tzw. technologia tłumaczenia bezpośredniego, której przykładem był właśnie słynny eksperyment z Georgetown.
Oprócz tego znane są tzw. systemy przekładu składniowego oraz, stanowiące w pewnym sensie ich rozwinięcie, systemy powierzchniowego transferu semantycznego, których działanie opiera się na drzewie składników syntaktycznych, według którego algorytm programu podstawia odpowiednie elementy zdania do tekstu przekładu. Program wykorzystuje różne stopnie złożoności drzew syntaktycznych, w tym najprostsze:
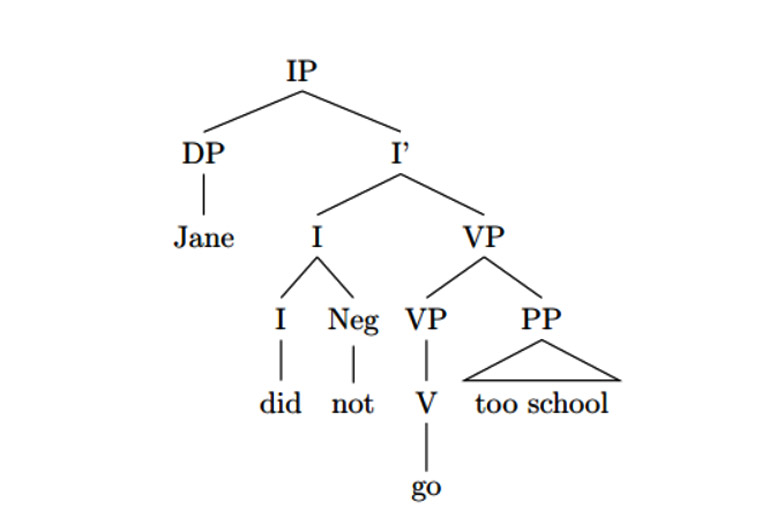 Źródło: https://linguistics.stackexchange.com/questions/19006/analyzing-negation-with-a-syntactic-tree.
Źródło: https://linguistics.stackexchange.com/questions/19006/analyzing-negation-with-a-syntactic-tree.
Jak i nieco bardziej skomplikowane:
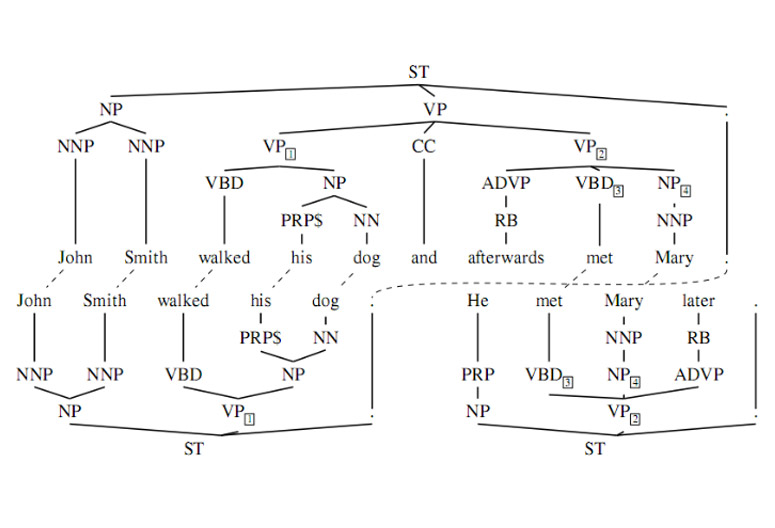 Źródło: https://tex.stackexchange.com/questions/111196/how-to-create-syntactic-trees-and-align-them-in-latex.
Źródło: https://tex.stackexchange.com/questions/111196/how-to-create-syntactic-trees-and-align-them-in-latex.
Oprócz tego istnieją także tzw. międzyjęzykowe systemy tłumaczenia automatycznego wykorzystujące uniwersalny język pośredni (tzw. interlingwa), gdzie tłumaczenie jest dwuetapowe i zaczyna się od przekładu z języka wyjściowego na wspomnianą interlingwę, a kończy na tłumaczeniu z interlingwy na język docelowy. Dalej mamy do czynienia z tzw. tłumaczeniem maszynowym opartym na przykładach, które wykorzystuje wcześniej przetłumaczone i podzielone na mniejsze fragmenty teksty, gdzie tłumaczenie jest tworzone na podstawie aproksymacji i podobieństwa do innych, wcześniej przetłumaczonych tekstów przechowywanych w specjalnej bazie danych. Najbardziej popularny i, jak się wydaje (przynajmniej do niedawna), zdecydowanie najbardziej skuteczny jest system tzw. tłumaczenia statystycznego oparty na modelach statystycznych tworzonych na podstawie analizy korpusu tekstów równoległych w danej parze językowej. System ten wykorzystuje następujący wzór:
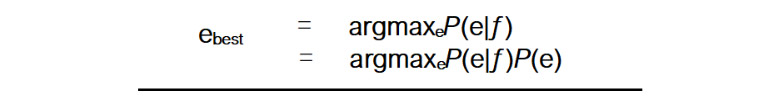
z którego wynika, że równie istotny, jak przechowywany w programie model języka P(e) jest zbiór danych wejściowych. Słowem, im więcej danych, tym lepsze działanie algorytmu systemu.
Żaden system nie działa jak ludzki mózg
Mechanizm tłumaczenia statystycznego leży u podstaw wspomnianego już, bardzo popularnego, programu google translate, który z tego powodu często nieprecyzyjnie jest określany jako system, który „sam się uczy”. Oczywiście jest to bardzo duże uproszczenie, ponieważ program ten wykonuje operacje statystyczne na wprowadzanym do niego materiale, czyli wykorzystuje zaawansowany rachunek prawdopodobieństwa, przy czym prawdopodobieństwo jest tu wprost proporcjonalne do ilości danych wejściowych (korpus dwujęzyczny). Mówiąc krótko – program niczego się nie „uczy”, chociaż faktycznie z czasem zdaje się działać coraz lepiej.
Warto jednak bardzo wyraźnie zaznaczyć, że żaden z wyżej wymienionych systemów MT nie działa w taki sposób, jak ludzki mózg. Są to jedynie różnego rodzaju zbiory mechanizmów i algorytmów, które w połączeniu ze sobą potrafią, w określonych sytuacjach i w określonym zakresie, doprowadzić do uzyskania zadowalających rezultatów. Na przykład maszynowe tłumaczenie symultaniczne mowy (w dzisiejszych czasach możliwe) to po prostu połączenie algorytmu rozpoznawania głosu z silnikiem tłumaczenia statystycznego (ze wszystkimi ograniczeniami, które niosą za sobą oba te mechanizmy). Oczywiście nie sposób nie wspomnieć w tym miejscu o bardzo głośnych w ostatnim czasie tzw. sztucznych sieciach neuronowych, jednak wydaje się, że przypisywanie im zdolności replikowania procesów zachodzących w mózgu człowieka jest nieco przesadzone i także wynika z nieznajomości zasad ich działania. Natomiast na jakąkolwiek miarodajną ocenę skuteczności silników MT opartych na SSN będziemy musieli jeszcze długo czekać.
Czy komputer zastąpi czy ułatwi pracę tłumaczy?
Wróćmy jednak do najważniejszej kwestii, czyli pytania o to, czy w najbliższej przyszłości są szanse na to, że komputer zastąpi tłumacza. Odpowiedź brzmi: to nie jest właściwe pytanie. Od kiedy zaczęliśmy korzystać z komputerowych edytorów tekstu, wiele zadań tradycyjnie wykonywanych ręcznie zostało scedowanych na naszego elektronicznego pomocnika. Komputer sprawdza za nas pisownię, poprawia formatowanie tekstu, rysuje tabele, umożliwia automatyczne wyszukiwanie, wstawianie i zastępowanie słów. Od kiedy mamy możliwość pracy z nowoczesnymi narzędziami OCR komputer rozpoznaje zeskanowane pismo lub druk i zamienia je na edytowalny tekst elektroniczny. Istnieją więc (i w rzeczy samej od dawna są już bardzo rozpowszechnione) narzędzia umożliwiające rozpoznawanie, a następnie wyszukiwanie i zastępowanie fragmentów tekstu dowolnej długości, jak również narzędzia sprawdzające pisownię i (do pewnego stopnia, chociaż postęp w tej dziedzinie także jest widoczny) gramatykę. W rezultacie przetłumaczenie dokumentu dostarczonego w druku lub w formie kiepskiej jakości skanu zajmuje dziś znacznie mniej czasu niż kilka, lub kilkanaście lat temu. Nie trzeba nikomu wyjaśniać, że bez komputerów i nowoczesnego oprogramowania nie byłoby to możliwe. Nikt też raczej nie zaprzeczy, że konwersja, formatowanie, sprawdzanie pisowni i przeszukiwanie tekstu to zadania, których tłumacze pozbyli się raczej chętnie. Nikt raczej nie chce wrócić do ręcznego przepisywania tekstu czy też mozolnego sprawdzania pisowni każdego pojedynczego słowa, o przeszukiwaniu długich dokumentów w poszukiwaniu wszystkich zastosowań danego terminu (np. w celu jego zastąpienia innym) nie wspominając.
To nie wszystko – pomyślmy o współczesnych narzędziach do tłumaczenia wspomaganego komputerowo. Jeden z podstawowych mechanizmów działania każdego programu CAT, czyli system pamięci tłumaczeniowych, to przecież nic innego, jak tłumaczenie maszynowe oparte na przykładach, o którym mówiliśmy wcześniej. Co więcej, stosowane w tych narzędziach bazy terminologiczne automatycznie podpowiadają nam terminy (tłumaczenie bezpośrednie), a mechanizmy typu „fragment assembly” próbują samodzielnie „składać” zdania na zasadzie przekładu składniowego, który także wymieniliśmy wcześniej jako kolejny z mechanizmów tłumaczenia maszynowego. Gdyby zapytać regularnego użytkownika programu CAT (a trzeba zaznaczyć, że coraz trudniej spotkać kogoś, kto tych narzędzi nie używa w ogóle), czy miałby ochotę przetłumaczyć np. sprawozdanie finansowe w formie tabelarycznej w programie MS Word, odpowiedź z pewnością byłaby przecząca.
W takim razie co się tak naprawdę dzieje? Wygląda na to, że na naszych oczach pisana jest historia zawodu tłumacza. Jesteśmy w stanie ją obserwować, ponieważ technologia rozwija się w niewiarygodnie szybkim (i stale rosnącym) tempie. Tłumacze pracujący w swoim zawodzie od 10 lub więcej lat pamiętają, jak komputery stopniowo przejmowały na siebie coraz więcej zadań. Ale czy zostali przez nie zastąpieni?
Wróćmy na chwilę do eksperymentu w Georgetown. Z perspektywy historycznej możemy dziś z całą pewnością powiedzieć, że euforia, która po nim nastąpiła, była przedwczesna. Czy to samo można stwierdzić teraz? Słowem – czy nadal prawdą jest, że automatyczne tłumaczenie dobrej jakości nadal pozostaje bardziej życzeniem, niż realnym celem do osiągnięcia w najbliższej przyszłości? Odpowiedź brzmi – to zależy. Mówiąc konkretniej – to zależy od tego, co uważamy za „tłumaczenie dobrej jakości”. Jeżeli maszynowy przekład kilkudziesięciu zdań na zasadzie tłumaczenia bezpośredniego, bez żadnej analizy relacyjnej w zakresie składni i z minimalnym zasobem leksykalnym w pamięci można było okrzyknąć tryumfem ówczesnej technologii, działanie dzisiejszych statystycznych silników MT podobnych do google translate z całą pewnością również powinno zostać uznane za sukces. Prawdziwym problemem tutaj nie jest jednak to, czy technologia jest w stanie wykonać swoją pracę, ale jak dobrze ta praca jest faktycznie wykonana i czy spełnia swoją funkcję do danego celu. Czy poprzednie zdanie pasuje do stylu całego artykułu? Zostało przetłumaczone z języka angielskiego najnowszą wersją google translate1. Doskonałym podsumowaniem tego problemu jest słynne retoryczne pytanie, które często pojawia się w kontekście skuteczności tłumaczenia maszynowego: „Is ‘good enough’ good enough?”
Jest na rynku miejsce zarówno na tłumaczenia automatyczne, jaki i na profesjonalne tłumaczenia
Podsumowując – rozwój komputerów i oprogramowania nie zagraża tłumaczom, ponieważ jego celem jest ułatwienie ich pracy. Natomiast tłumaczenie maszynowe to narzędzie, które spełnia określone zadanie i dla którego na pewno znajdzie się miejsce na rynku. Tego typu rozsądną politykę stosuje np. firma Microsoft, która niektóre teksty na swoich stronach internetowych, w tym informacje techniczne, instrukcje obsługi i teksty pomocy tłumaczy na języki obce maszynowo w oparciu na własnym, spersonalizowanym i stale rozwijanym silniku MT, ale np. tłumaczenie tekstów użytkowych, w tym umów, licencji, tekstów o charakterze reklamowym i promocyjnym itd. zleca tłumaczom (agencjom tłumaczeń). Oczywiście możliwe są na tym polu różne błędy i nadużycia. Dla przykładu, Urząd Patentowy RP nie zapewnia anglojęzycznej wersji swojej strony internetowej, zamiast tego stosując na niej tzw. wtyczkę do google translate. Takie działanie można uznać za błąd, ponieważ dostarczenie angielskich odpowiedników specjalistycznych słów i wyrażeń z dziedziny krajowego prawa własności intelektualnej, jak również tłumaczenia tekstów objaśniających różne zagadnienia z tej gałęzi prawa nie powinno być powierzane narzędziom MT, które w oczywisty sposób do tego celu się nie nadają (co, mam nadzieję, jest w tym momencie zupełnie jasne i nie będzie postrzegane jako próba subiektywnej oceny).
Powiedzmy to jeszcze raz: pytanie o to, czy komputer zastąpi tłumacza, jest nieprecyzyjne. Można powiedzieć nawet więcej: to nie jest to pytanie, które powinniśmy sobie teraz zadawać. Właściwe pytanie brzmi tak: skoro komputery coraz bardziej wyręczają tłumaczy, co trzeba zrobić, aby móc z tej pomocy korzystać? Tak naprawdę komputery zaczną zastępować tłumaczy tylko i wyłącznie wtedy, gdy tłumacze będą je ignorować. Z wyjątkiem nielicznych i bardzo specjalistycznych sektorów rynku przekładu (np. tłumaczenie tekstów literackich lub, do pewnego stopnia, akademickich), bardzo trudno jest dziś znaleźć pracę w tym zawodzie bez przynajmniej podstawowej znajomości jednego programu CAT i narzędzia OCR, o umiejętności korzystania z edytora tekstu i arkuszy kalkulacyjnych nie wspominając. Technologia to ekspres, który będzie dalej pędzić naprzód bez względu na to, czy będziemy na jego pokładzie. Postarajmy się więc jak najszybciej o bilet. Najlepiej przy oknie.

O autorze
Marcin Szwed – filolog anglista, czynny tłumacz LSP, tłumacz ustny i dydaktyk przekładu, prowadzi warsztaty z zakresu tłumaczenia tekstów specjalistycznych i tłumaczenia konferencyjnego, wykładowca Uniwersytetu SWPS i Uniwersytetu Warszawskiego, tłumacz przysięgły języka angielskiego od 2006 r. specjalizujący się w dziedzinach prawa (w tym prawa UE), techniki budowlanej i farmacji.
1The real problem here is not, however, whether technology is able to do its job, but how good that job is actually done and if it fulfils its function for the given purpose.





